Fusion Fundamentals #3 - Cloud - Ingest, Store, and Consume OT Data
The third part of the Fusion Fundamentals series with Suchi Badrinarayanan, Business Consultant, at Fusion. This series focuses on liberating and normalizing OT data to accelerate enterprise-wide adoption and high business value realization of AI/ML. The third topic is Cloud - Ingest, Store, and Consume OT Data.
Read the video transcript below for your own convenience:
Our Mission

What we are trying to do at Fusion and what we’ve achieved with many companies is creating an Industrial Analytics Data Hub. So that any use case can grab that data and provide business value for their company; so in less than two weeks, we can typically install this and have data flowing. We're able to do that securely and in a way where the data is reliably moved over. Then we can also extract any additional information that's within that system in the first place. So that means any metadata that's relevant, any hierarchical data that's relevant and combining all these data into a single repository – a single data hub where it's then applicable for any use case.
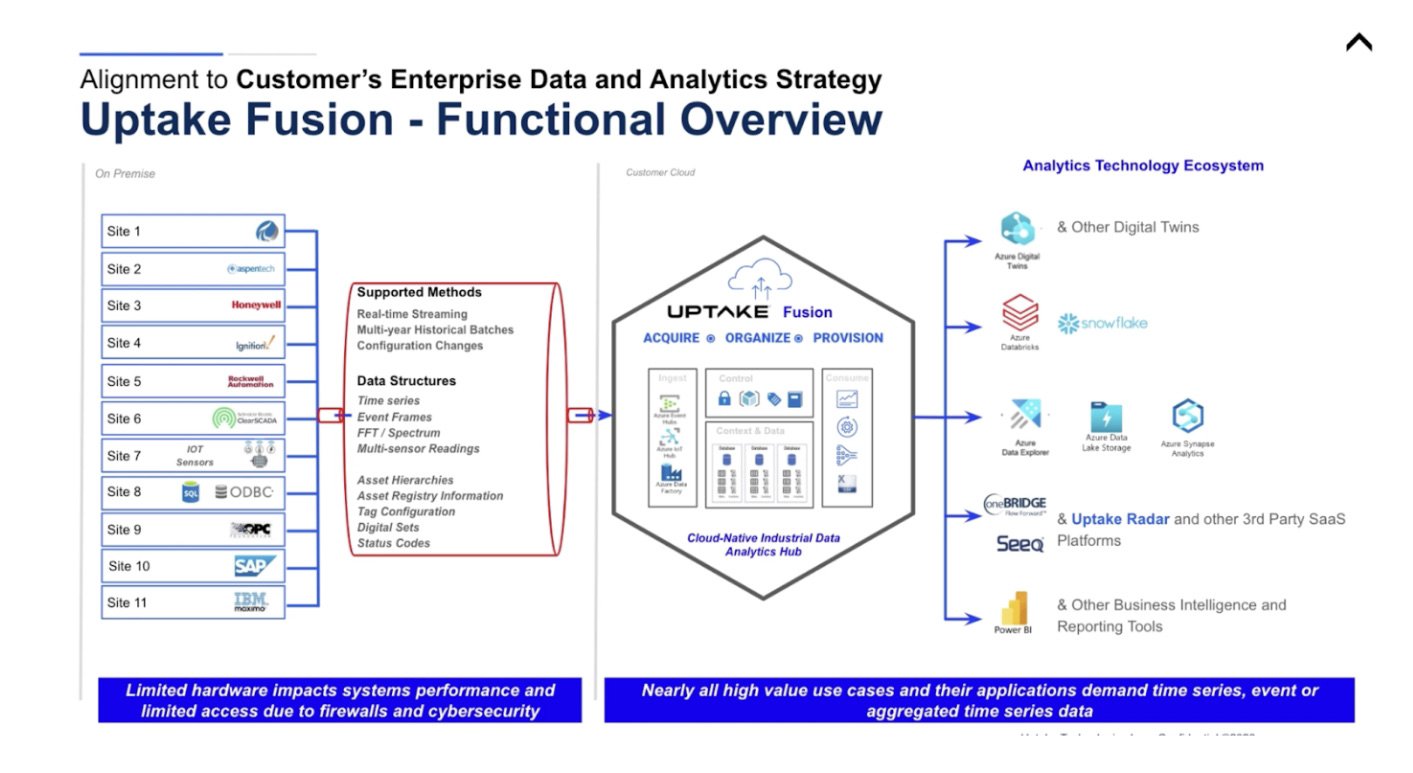
What Makes Fusion Unique?
We have first-party connectors to a lot of the sources that you see on the left side of the photo above. There are some that we're still working on that we should have by this year. But those first-party connectors allow us to do some interesting things, such as having very low latency for real-time streaming data. This allows us to do multi-year historical batches that can be different for different tags depending on the use case. This also allows us to view any configuration changes that happen in the source system, such as if the hierarchy changes or if the metadata changes. These first-party connectors are constantly looking at that OTsource and making sure that if any changes are occurring on that system that they move over as well, too, and get reflected in the cloud.
Also, if available, we can also move over event frames or any sort of right vibration analysis that happens, anything from IoT sensors, which is becoming very popular now. We can move all of that data over in a secure manner.
Once that data is available to us. We typically install our product fusion in our customers' Cloud. There are a couple of cases where we host for various reasons, but for security purposes in terms of data, most of our customers ask us to implement this solution in their Azure tenant. We also do not try to mine that data for any reason. That data typically comes in through an IoT hub or equivalent. It comes in through the most secure manner and then can be used for any sort of use case that you can imagine.
For example, we have a lot of customers using Azure Data Explorer, but if you prefer Synapse, that's an easy thing for us to manage as well. Or the customer can you other third-party solutions.
All in all, this allows Fusion to be that central point where all of that data comes in. It's normalized, so you are querying it all the same way. It’s mapped to OPC standard and has some other data cleansing.
When your consumers of that data are using that data, we ensure
The data is fully complete and reflects the original source.
That the data contains all of the metadata and hierarchical information from that source, but also it's cleansed and purposefully created to allow you to do your analytics and spend as least time cleansing that data as possible.